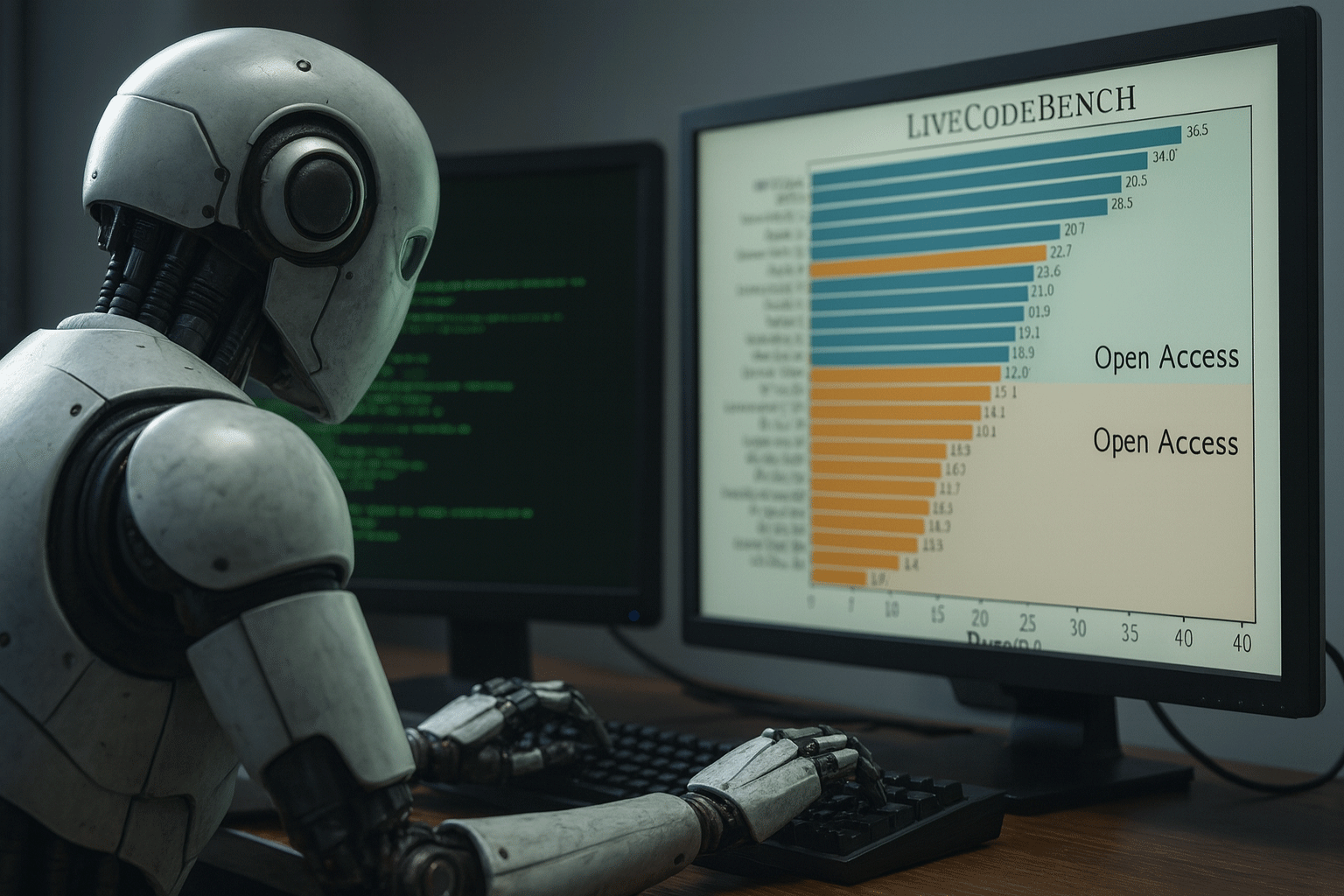
What is LiveCodeBench?
LiveCodeBench is a new tool designed to test the coding abilities of artificial intelligence models. It is what researchers call a “benchmark”, a way of comparing systems against a standard set of problems.
Unlike older benchmarks, LiveCodeBench is constantly updated with new tasks. This is important because AI models learn from vast amounts of internet data. If a benchmark problem already exists in that data, there is a risk the AI is simply recalling a solution rather than solving the problem. LiveCodeBench’s rolling updates help avoid this issue and keep the test “contamination-free”.
Crucially, the benchmark goes beyond simply asking a model to generate code. It also tests whether the model can:
- Repair its own mistakes when code fails.
- Predict the output of test cases.
- Execute code correctly, not just write it.
This broader approach reflects the real-world challenges of software engineering, where spotting errors and reasoning about outputs can be as important as writing the initial code.
How is Performance Measured?
LiveCodeBench uses two key methods to measure success:
- Pass@k: This records whether the AI solves a problem within its first k attempts. The strictest measure, Pass@1, asks if the model gets it right first time, which is a strong sign of genuine understanding.
- Bayesian Elo rating: Borrowed from competitive programming, this assigns each model a difficulty-adjusted score. Like human players on coding sites, models can be ranked as “Expert” or “Grandmaster” depending on their performance.
By combining these approaches, LiveCodeBench captures not only accuracy but also problem-solving efficiency.
What Have We Learned So Far?
Researchers have tested 29 different models on the platform, and the results show a mixed picture.
Closed models, which are available only through paid APIs such as GPT-4-turbo and Claude-3-Opus, currently outperform most open-source alternatives. However, some larger open models, such as DS-Ins-33B and Phind-34B, show promising results.
Different models also excel at different tasks. Claude-3-Opus does better than GPT-4-turbo when predicting test outputs, but GPT-4-turbo is stronger at generating correct code from scratch. Another model, Mistral-Large, shows skill at interpreting and executing code, an ability closer to human reasoning.
However, when it comes to the very toughest challenges rated above 3000 Elo, similar to elite Olympiad problems, no model has yet succeeded. This highlights how far AI still has to go before matching the best human programmers.
Why Does This Matter?
As AI tools become more common in software development, knowing their strengths and weaknesses is essential. An AI that produces neat code but struggles with edge cases could still introduce costly errors.
LiveCodeBench not only ranks models but also diagnoses where they go wrong. Human experts audit failed submissions to see whether the problem was sloppy implementation, flawed reasoning, or a missed creative insight. This level of detail gives researchers clues on how to train future models.
The Bigger Picture
In the race to build smarter AI, LiveCodeBench offers a fairer and more rigorous way to track progress. It keeps benchmarks fresh, reduces the risk of memorisation, and provides fine-grained insights into model performance.
For now, AI is proving strong at writing reliable code, but creative reasoning remains its weak point. Human programmers, especially at the highest levels of competition, still hold the upper hand.







